How to use composite indexes to speed up time-series queries
Appropriately ordered indexes can speed up queries, sometimes by orders of magnitude.
(Thanks to Matvey Arye and Sven Klemm for their contributions to this post.)
As a time-series database built on PostgreSQL, TimescaleDB utilizes the relational model to store time-series data. This means you can store relational data right alongside time-series data, join across tables, and best of all, use SQL. When it comes to really deriving insights from time-series data, we find that using an expressive querying language that is a well understood industry standard like SQL makes it easier to adopt and integrate with other tools.
One common question we get from users is how to build the right indexes for time-series data. As you probably know, triggering the use of an index in a query can be the difference between a query returning in a couple milliseconds vs a couple seconds, hours, or even days! This makes sense particularly because the same indexes you would build within PostgreSQL are probably different once you bring timestamps into the mix. At a deeper level, TimescaleDB breaks data into chunks based on time intervals and then builds indexes on each chunk (rather than globally). So, there are some specific things to think about when building indexes to support different types of queries.
To come up with a really simplistic example, let’s pretend that you have a bunch of devices that track 1,000 different retail stores. You have a hundred devices per store, and 5 different types of devices. All of these devices report metrics as float values, and you decide to store all the metrics in the same table. A simple table might use the following schema:
create table devices (
time timestamptz,
device_id int,
device_type int,
store_id int,
value float
);If you enable TimescaleDB on this table for faster time-series queries, TimescaleDB automatically generates an index on the time column if one does not exist.

However, you might not always want to query just by time. For example, you might want to query data from the last month for just a given device_id, or maybe you want to query data from the last three months for just a store_id. What types of indexes might you build then?
Since we are talking about time-series, we want to keep the index we have on time so that we can quickly filter for a given time range. However, we also want to be able to quickly pull data based on device_id or store_id. That’s when composite indexes are really powerful!
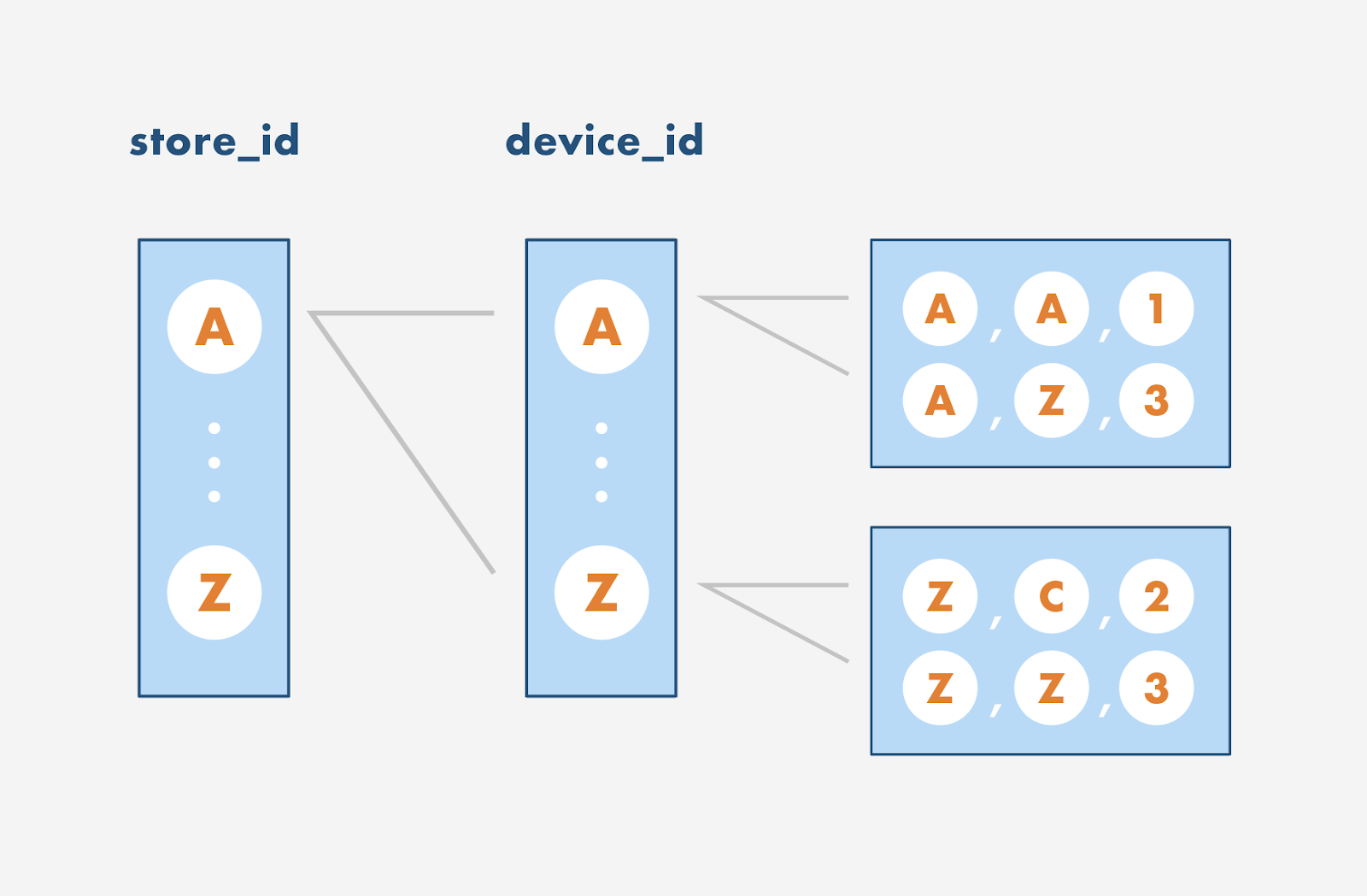
The secret to remember when building indexes is that order matters. Essentially, when PostgreSQL builds an index, it sorts based on the order of the composite index. As an example, let’s explore a composite index on (store_id, device_id, time). This is an index that you might naturally guess to build if you know that you want to query on store_id, device_id, and time. PostgreSQL will essentially build something like the below:

You can imagine that an index on(store_id, device_id, time) defines an ordering like a phone book indexed by last_name, first_name, middle_name. In a phone book, you’ll first have all the last names sorted in order. Then, all the first names associated with a given last name are sorted in order. Finally, all the middle names with the same last name and first name are sorted in order. The same thing happens when you build an index on (store_id, device_id, time). Values are first ordered by store_id. Values with device_ids that have the same store_id are then ordered. Finally, values with the same store_id and device_id are ordered. The key to remember is that indexes only speed up queries if you access a continuous portion of this list:
SELECT * FROM devices WHERE store_id = x: This would correspond to the portion of the list with a specificstore_id. This index is effective for this query but is bloated; an index on juststore_idwould suffice.SELECT * FROM devices WHERE store_id = x, time > 10: This is not effective because it would need to scan multiple sections of the list since the part of the list that contains data fortime > 10for device A would be located in a different section than for device Z. In this case, you could consider building an index on(store_id, time).SELECT * FROM devices WHERE device_id = M, time > 10: This index would be useless since device M would be located in completely different sections of the list depending on thestore_id.SELECT * FROM devices WHERE store_id = M, device_id = M, time > 10: This is the perfect query for this index. It narrows down the list to a very particular portion of the list.
A good rule of thumb with composite indexes is to think in layers. The first few layers are the columns that you typically want to run an equality operator on (for example, store_id = 1 or device_id = 2). The last layer can be used with range operators (i.e. time > 10). To use an index in a query, the query must use some prefix of the layers.
Ok, so what indexes should you build then? If you want to query all devices by store, a good index would be on (store_id, time). If you want to query specific devices by store, a good index would be on (store_id, device_id, time). If you want to query specific devices by type, you could build an index on (device_type, device_id, time).
However, if you only query for device_type and not device_id, you should only build an index on (device_type, time). The important thing to remember is that there’s a trade-off: unnecessary indexes also take up more space. Indexes also need to be updated during inserts or updates (and deletes), ultimately slowing down those operations.
Seeing composite indexes in practice
As a more tangible example of this in practice, we created a naive index (store_id, device_id, time) on our existing table. We looked at a couple different EXPLAINs for the four queries we had wanted to speed up above. These EXPLAINs were run on a local machine with a generated dataset, so what really matters here is comparing the performance characteristics across different queries and not on the raw numbers themselves. If you want to run this yourself, make sure to run ANALYZE after adding a new index so that PostgreSQL recalculates table statistics.
Case 1: store_id = x
If you remember from before, just querying on store_id is fine since it’s the first element in our naive index. However, it’s a little unnecessary to include device_id in that index as well. In the below EXPLAIN, you can see how the query planner still chooses to use the naive index.
QUERY PLAN
------------------------------------------------------------
Append (cost=0.00..134725.12 rows=80130 width=28) (actual time=0.049..28.326 rows=84500 loops=1)
Buffers: shared hit=17739
-> Seq Scan on devices (cost=0.00..0.00 rows=1 width=28) (actual time=0.008..0.008 rows=0 loops=1)
Filter: (store_id = 1)
-> Index Scan using _hyper_2_6_chunk_naive_idx on _hyper_2_6_chunk (cost=0.43..2432.34 rows=1445 width=28) (actual time=0.039..1.045 rows=1500 loops=1)
Index Cond: (store_id = 1)
Buffers: shared hit=317
-> Index Scan using _hyper_2_7_chunk_naive_idx on _hyper_2_7_chunk (cost=0.56..33436.19 rows=19886 width=28) (actual time=0.030..6.107 rows=21000 loops=1)
Index Cond: (store_id = 1)
Buffers: shared hit=4408
-> Index Scan using _hyper_2_8_chunk_naive_idx on _hyper_2_8_chunk (cost=0.56..33496.36 rows=19924 width=28) (actual time=0.010..4.809 rows=21000 loops=1)
Index Cond: (store_id = 1)
Buffers: shared hit=4408
-> Index Scan using _hyper_2_9_chunk_naive_idx on _hyper_2_9_chunk (cost=0.56..33400.79 rows=19863 width=28) (actual time=0.009..4.670 rows=21000 loops=1)
Index Cond: (store_id = 1)
Buffers: shared hit=4408
-> Index Scan using _hyper_2_10_chunk_naive_idx on _hyper_2_10_chunk (cost=0.56..31959.44 rows=19011 width=28) (actual time=0.010..4.510 rows=20000 loops=1)
Index Cond: (store_id = 1)
Buffers: shared hit=4198
Planning time: 0.838 ms
Execution time: 32.445 ms
(21 rows)
Time: 33.880 msTo improve the performance here, we’ve created a more efficient, less bloated index just on store_id (named store_idx). Notice how we are now using that index to find elements where store_id = 1, and the execution time is slightly reduced.
QUERY PLAN ------------------------------------------------------------------ Append (cost=0.00..2902.53 rows=80307 width=28) (actual time=0.022..21.981 rows=84500 loops=1)
Buffers: shared hit=869
-> Seq Scan on devices (cost=0.00..0.00 rows=1 width=28) (actual time=0.003..0.003 rows=0 loops=1)
Filter: (store_id = 1)
-> Index Scan using _hyper_2_6_chunk_store_idx on _hyper_2_6_chunk (cost=0.43..55.82 rows=1451 width=28) (actual time=0.018..0.328 rows=1500 loops=1)
Index Cond: (store_id = 1)
Buffers: shared hit=19
-> Index Scan using _hyper_2_7_chunk_store_idx on _hyper_2_7_chunk (cost=0.44..720.09 rows=19980 width=28) (actual time=0.014..3.975 rows=21000 loops=1)
Index Cond: (store_id = 1)
Buffers: shared hit=215
-> Index Scan using _hyper_2_8_chunk_store_idx on _hyper_2_8_chunk (cost=0.44..719.86 rows=19967 width=28) (actual time=0.012..3.716 rows=21000 loops=1)
Index Cond: (store_id = 1)
Buffers: shared hit=215
-> Index Scan using _hyper_2_9_chunk_store_idx on _hyper_2_9_chunk (cost=0.44..718.63 rows=19897 width=28) (actual time=0.012..3.628 rows=21000 loops=1)
Index Cond: (store_id = 1)
Buffers: shared hit=215
-> Index Scan using _hyper_2_10_chunk_store_idx on _hyper_2_10_chunk (cost=0.44..688.13 rows=19011 width=28) (actual time=0.012..3.372 rows=20000 loops=1)
Index Cond: (store_id = 1)
Buffers: shared hit=205
Planning time: 0.487 ms
Execution time: 25.904 ms
(21 rows)
Time: 26.844 ms
Case 2: store_id = x, time > (now()-'7 days')
As discussed before, this query would not effectively use our naive index on (store_id, device_id, time) because time is ordered by store_id and device_id, not just store_id. This means you are scanning across multiple sections of the list to find all elements where time > (now()-'7 days'). The EXPLAIN below shows how this query uses the naive index.
QUERY PLAN
-------------------------------------------------------------------- Custom Scan (ConstraintAwareAppend) (cost=0.00..34212.12 rows=19966 width=28) (actual time=0.071..11.638 rows=21000 loops=1)
Hypertable: devices
Chunks left after exclusion: 2
Buffers: shared hit=4488
-> Append (cost=0.00..34212.12 rows=19966 width=28) (actual time=0.069..9.496 rows=21000 loops=1)
Buffers: shared hit=4488
-> Index Scan using _hyper_2_9_chunk_naive_idx on _hyper_2_9_chunk (cost=0.57..2150.08 rows=932 width=28) (actual time=0.067..2.431 rows=1000 loops=1)
Index Cond: ((store_id = 1) AND ("time" > (now() - '7 days'::interval)))
Buffers: shared hit=290
-> Index Scan using _hyper_2_10_chunk_naive_idx on _hyper_2_10_chunk (cost=0.57..32037.10 rows=19030 width=28) (actual time=0.052..5.206 rows=20000 loops=1)
Index Cond: ((store_id = 1) AND ("time" > (now() - '7 days'::interval)))
Buffers: shared hit=4198
Planning time: 1.196 ms
Execution time: 13.053 ms
(14 rows)
Time: 14.962 ms
Let’s try the same query as above, but with a new index on (store_id, time)named store_time_idx.
QUERY PLAN
-------------------------------------------------------------------- Custom Scan (ConstraintAwareAppend) (cost=0.00..33782.19 rows=19994 width=28) (actual time=0.043..9.345 rows=21000 loops=1)
Hypertable: devices
Chunks left after exclusion: 2
Buffers: shared hit=244
-> Append (cost=0.00..33782.19 rows=19994 width=28) (actual time=0.041..6.894 rows=21000 loops=1)
Buffers: shared hit=244
-> Index Scan using _hyper_2_9_chunk_store_time_idx on _hyper_2_9_chunk (cost=0.57..1762.72 rows=986 width=28) (actual time=0.040..0.523 rows=1000 loops=1)
Index Cond: ((store_id = 1) AND ("time" > (now() - '7 days'::interval)))
Buffers: shared hit=16
-> Index Scan using _hyper_2_10_chunk_store_time_idx on _hyper_2_10_chunk (cost=0.57..31996.34 rows=19004 width=28) (actual time=0.038..4.278 rows=20000 loops=1)
Index Cond: ((store_id = 1) AND ("time" > (now() - '7 days'::interval)))
Buffers: shared hit=228
Planning time: 1.094 ms
Execution time: 10.848 ms
14 rows)
Time: 12.569 msYou can see how the execution time is slightly faster when you use a less bloated index.
Case 3: device_id = M, time > (now()-'7 days')
This index would be useless since device M would be located in completely different sections of the list depending on the store_id. The query planner still chooses to use the naive index, but the query is pretty slow compared to the other queries we ran above.
QUERY PLAN
-------------------------------------------------------------------- Custom Scan (ConstraintAwareAppend) (cost=0.00..622571.78 rows=184804 width=28) (actual time=0.050..692.139 rows=210000 loops=1)
Hypertable: devices
Chunks left after exclusion: 2
Buffers: shared hit=200330
-> Append (cost=0.00..622571.78 rows=184804 width=28) (actual time=0.048..678.262 rows=210000 loops=1)
Buffers: shared hit=200330
-> Index Scan using _hyper_2_9_chunk_naive_idx on _hyper_2_9_chunk (cost=0.57..295014.36 rows=9466 width=28) (actual time=0.047..325.640 rows=10000 loops=1)
Index Cond: ((device_id = 1) AND ("time" > (now() - '7 days'::interval)))
Buffers: shared hit=82522
-> Index Scan using _hyper_2_10_chunk_naive_idx on _hyper_2_10_chunk (cost=0.57..327550.15 rows=175334 width=28) (actual time=0.018..339.724 rows=200000 loops=1)
Index Cond: ((device_id = 1) AND ("time" > (now() - '7 days'::interval)))
Buffers: shared hit=117808
Planning time: 1.196 ms
Execution time: 699.942 ms
(14 rows)
Time: 701.886 msInstead, we build an index on (device_id, time) to speed things up. You can see what a big difference this makes in query performance.
QUERY PLAN
-------------------------------------------------------------------- Custom Scan (ConstraintAwareAppend) (cost=0.00..126565.09 rows=196917 width=28) (actual time=0.031..106.276 rows=210000 loops=1)
Hypertable: devices
Chunks left after exclusion: 2
Buffers: shared hit=44047
-> Append (cost=0.00..126565.09 rows=196917 width=28) (actual time=0.030..89.040 rows=210000 loops=1)
Buffers: shared hit=44047
-> Index Scan using _hyper_2_9_chunk_device_idx on _hyper_2_9_chunk (cost=0.57..8876.18 rows=8913 width=28) (actual time=0.029..3.551 rows=10000 loops=1)
Index Cond: ((device_id = 1) AND ("time" > (now() - '7 days'::interval)))
Buffers: shared hit=2101
-> Index Scan using _hyper_2_10_chunk_device_idx on _hyper_2_10_chunk (cost=0.57..117681.65 rows=188000 width=28) (actual time=0.017..68.979 rows=200000 loops=1)
Index Cond: ((device_id = 1) AND ("time" > (now() - '7 days'::interval)))
Buffers: shared hit=41946
Planning time: 0.764 ms
Execution time: 115.630 ms
(14 rows)
Time: 117.197 ms
Case 4: store_id = x, device_id = M, time > (now()-'7 days')
This is the perfect query for this index. It narrows down the list to a very particular portion of the list. You can see how quickly it executes using the naive index like we want it to: 3 milliseconds vs. the hundreds of milliseconds above.
QUERY PLAN
-------------------------------------------------------------------- Custom Scan (ConstraintAwareAppend) (cost=0.00..96.79 rows=191 width=28) (actual time=0.042..0.374 rows=210 loops=1)
Hypertable: devices
Chunks left after exclusion: 2
Buffers: shared hit=51
-> Append (cost=0.00..96.79 rows=191 width=28) (actual time=0.041..0.315 rows=210 loops=1)
Buffers: shared hit=51
-> Index Scan using _hyper_2_9_chunk_naive_idx on _hyper_2_9_chunk (cost=0.57..5.81 rows=8 width=28) (actual time=0.039..0.049 rows=10 loops=1)
Index Cond: ((store_id = 1) AND (device_id = 1) AND ("time" > (now() - '7 days'::interval)))
Buffers: shared hit=6
-> Index Scan using _hyper_2_10_chunk_naive_idx on _hyper_2_10_chunk (cost=0.57..85.03 rows=179 width=28) (actual time=0.042..0.211 rows=200 loops=1)
Index Cond: ((store_id = 1) AND (device_id = 1) AND ("time" > (now() - '7 days'::interval)))
Buffers: shared hit=45
Planning time: 1.503 ms
Execution time: 0.709 ms(
14 rows)
Time: 3.340 msIn short, the right type of query for this composite index reduced our query time by two or three orders of magnitude!
Next Steps
We hope this overview was useful to you and please stay tuned for more posts like this one. And in case you missed it, we recently announced that TimescaleDB 1.0 is production ready and encourage you to check out our GitHub page.
If you are new to TimescaleDB and ready to get started, follow the installation guide. If you have questions, we encourage you to join 1500+ member-strong Slack community. And if you are looking for enterprise-grade support and assistance please let us know.
Like this post and want to learn more? Sign up for the community mailing list below!
Interested in helping us build the next great open-source company? We’re hiring!



