Evaluating high availability solutions for TimescaleDB + PostgreSQL
How we evaluated several third-party tools and ultimately selected Patroni as our preferred method.
If you are working with a database, you already know that high availability (HA) is a requirement for any reliable system. A proper HA setup eliminates the problem of a single point-of-failure by providing multiple places to get the same data, and an automated way of selecting a proper location with which to read and write data. PostgreSQL typically achieves HA by replicating the data on the primary database to one or more read-only replicas.
Streaming replication is the primary method of replication supported by TimescaleDB. It works by having the primary database server stream its write-ahead log (WAL) entries to its database replicas. Each replica then replays these log entries against its own database to reach a state consistent with the primary database.
Unfortunately, such streaming replication alone does not ensure that users don’t encounter some loss of uptime (“availability”) when a server crashes. If the primary node fails or becomes unreachable, there needs to be a method to promote one of the read replicas to become the new primary. And the faster that this failover occurs, the smaller the window of unavailability a user will see. One simple approach to such promotion is by manually performing it through a few PostgreSQL commands. On the other hand, automatic failover refers to a mechanism by which the system detects when a primary has failed, fully removes it from rotation (sometimes called fencing), promotes one read replica to primary status, and ensures the rest of the system is aware of the new state.
While PostgreSQL supports HA through its various replication modes, automatic failover is not something it supports out of the box. There are a number of third-party solutions that provide HA and automatic failover for PostgreSQL, many of which work with TimescaleDB because they also leverage streaming replication.
In this post, we will discuss how we evaluated third-party failover solutions and share deployment information about the one that best fits with our requirements and constraints. We will also provide a series of HA/failover scenarios that users may encounter and how to deal with these scenarios.
Requirements and constraints
When looking for a failover solution to adopt, we decided that it should meet the following requirements (in no particular order):
- Does not require manual intervention for failover
- Supports streaming replication (TimescaleDB is not currently compatible with logical replication, so methods relying on this or other custom protocols did not make the cut)
- Supports different modes of replication (i.e. async vs synchronous commit)
- Handles network partitions (commonly called “split brain,” where multiple instances think they are the primary databases and different clients may write to different servers, leading to inconsistencies)
- Provides operational simplicity
- Supports load balancing the read replicas
- Plays nicely with cloud providers and containerized deployments
- Uses a known/understood algorithm for establishing consensus (This is needed to ensure that the entire system agrees on which node the primary is. Many solutions will offload the consensus work to a system that already has a robust implementation of a known consensus algorithm. Patroni and Stolon, for example, use an etcd cluster, which implements the Raft consensus algorithm, to manage the system’s state.)
- Supports the primary rejoining the cluster as a replica after being demoted and can become the primary again (failback)
- Can be managed manually through some kind of interface (CLI, HTTP, GUI, etc.)
- Has meaningful community adoption
- Released under a permissive license
Evaluation of solutions
To begin, we evaluated several popular HA/failover solutions and their support for our requirements. Some solutions were closed source and not free, so they were not considered. Others were disqualified because they did not support streaming replication or different replication modes.
A handful of the requirements (community adoption, interface for management, no manual intervention for failover) were met by all options considered. We decided to rule out solutions that involve determining the master by configuring a floating/virtual IP, which would not work well in many modern cloud environments without jumping through some operational hoops. Additionally, we eliminated Corosync and Pacemaker since they were older products that required extra complexity and specialized knowledge.
We concluded that Stolon and Patroni both were good solutions. Their architectures are both easy to understand which is in no small part thanks to the fact that they offload all of the consensus heavy-lifting to etcd/consul. Adoption wise, they appear to be on equal footing, at least by the metric of Github stars, followers, and forks. There is also a good deal of documentation and sample configurations/scripts for both of them.
Ultimately we decided to choose Patroni because of its slightly simpler architecture and more modular approach to load balancing. Where Stolon requires you to use its own stolon-proxy nodes for load balancing, Patroni exposes health checks on the PostgreSQL nodes and lets you use Kubernetes, AWS ELB, HA Proxy, or another proxy solution to deal with load balancing. Where Stolon requires an additional layer of standalone sentinel and proxy services, Patroni is able to offer the same HA guarantees with “bots” on the PostgreSQL instances communicating with an etcd cluster.
Getting started with Patroni
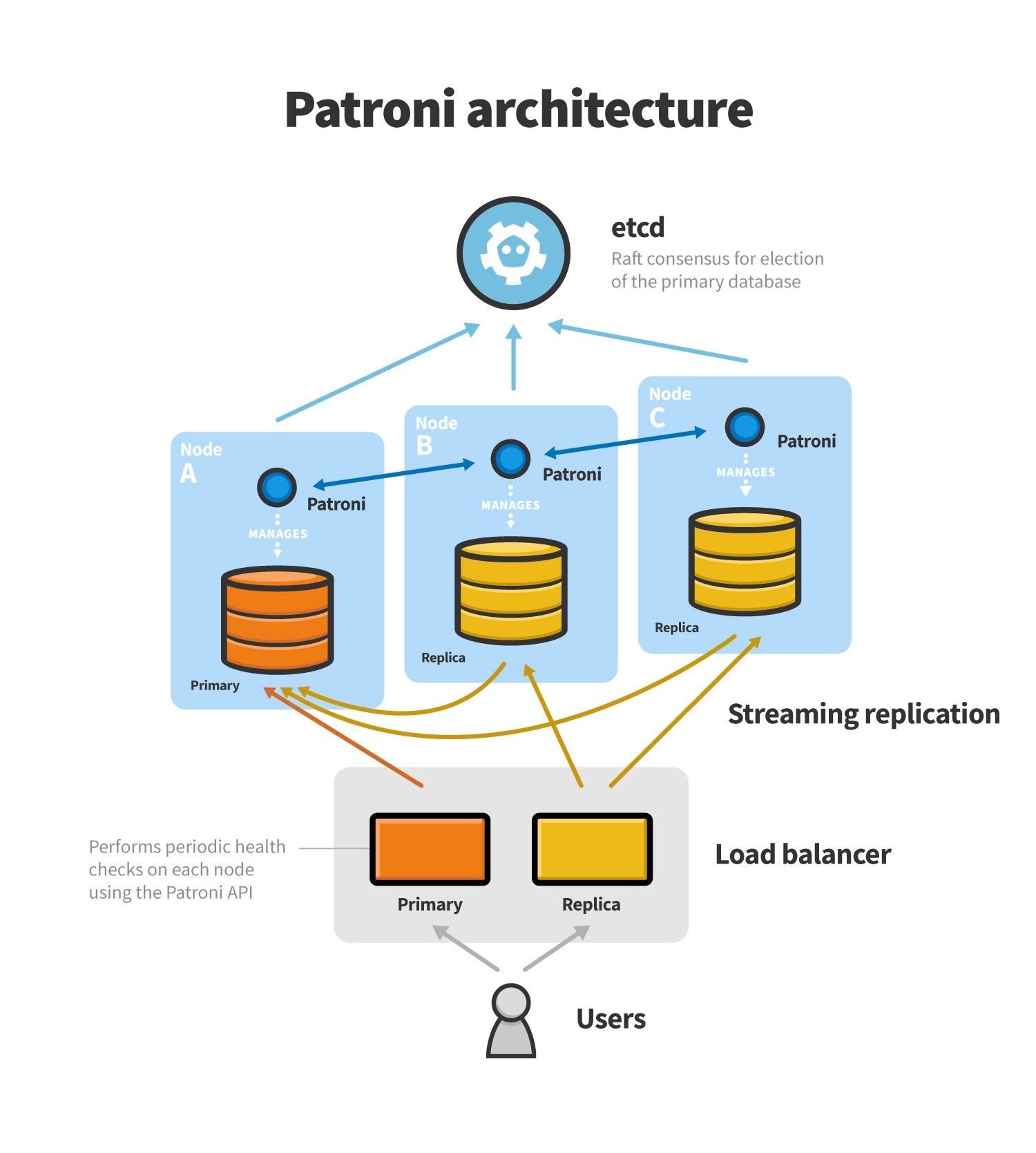
The core architecture of Patroni looks like this:

Each PostgreSQL node has a Patroni bot deployed on it. The bots are capable both of managing the PostgreSQL database and updating the distributed consensus system (etcd in this case although Zookeeper, Consul, and the Kubernetes API, which is backed by etcd, are also perfectly fine options). Etcd must be deployed in an HA fashion that allows its individual nodes to reach a quorum about the state of the cluster. This requires a minimum deployment of 3 etcd nodes.
Leader election is handled by attempting to set an expiring key in etcd. The first PostgreSQL instance to set the etcd key via its bot becomes the primary. Etcd ensures against race conditions with a Raft-based consensus algorithm. When a bot receives acknowledgement that it has the key, it sets up the PostgreSQL instance as a primary. All other nodes will see that a primary has been elected and their bots will set their PostgreSQL instances up as replicas.
The primary key has a short TTL attached to it. The primary’s bot must continually health check its PostgreSQL instance and update the primary key. If this doesn’t happen because (a) the node loses connectivity, (b) the database fails, or (c) the bot dies, the key will expire. This will cause the primary to be fully removed from the system. When the replicas see that there is no primary key, each replica will attempt to become the primary unless it is obvious through exchanging information between bots that one of the primaries should be elected over the other. The bots will then either choose an obvious candidate for promotion or both race to be promoted to the primary.
You can find this flow illustrated below:

Common failover scenarios
There are a number of failover scenarios we made sure to test when fully evaluating failover functionality. Some of the key ones to keep in mind are:
- The primary database crashes or is shut down
- The server with the primary database crashes, is shut down, or is unreachable
- A failed primary thinks it is a primary after failover
- Replica databases crash or shut down
- The Patroni bot on the primary goes down
- The Patroni bot on the replica goes down
- A replica is added to the cluster
Next steps
Above, we shared what we believe to be the best automatic failover solution for TimescaleDB users. While there are many third party solutions available, ultimately we went with Patroni because it combined robust and reliable failover with a simple architecture and easy-to-use interface.
If you are new to TimescaleDB and ready to get started, follow the installation instructions. If you have questions, we encourage you to join 1500+ member-strong Slack community. If you are looking for enterprise-grade support and assistance, please let us know.
Like this post? Interested in learning more? Follow us on Twitter or sign up for the community mailing list below!



