TimescaleDB vs. Amazon Timestream: 6,000x Higher Inserts, 5-175x Faster Queries, 150-220x Cheaper

This post compares TimescaleDB and Amazon Timestream across quantitative and qualitative dimensions.
Yes, we are the developers of TimescaleDB, so you might quickly disregard our comparison as biased. But if you let the analysis speak for itself, you’ll find that we stay as objective as possible and aim to be fair to Amazon Timestream in our testing and results reporting.
Also, if you want to check our work or run your own analysis, we provide all our testing via the Time Series Benchmark Suite, an open-source project that anyone can use and contribute to.
About TimescaleDB and Amazon Timestream
TimescaleDB, first launched in April 2017, is today the industry-leading relational database for time series, open-source, engineered on top of PostgreSQL, and offered via download or as a fully managed service on AWS.
The TimescaleDB community has become the largest developer community for time-series data: tens of millions of downloads; over 500,000 active databases; organizations like AppDynamics, Bosch, Cisco, Comcast, Credit Suisse, DigitalOcean, Dow Chemical, Electronic Arts, Fujitsu, IBM, Microsoft, Rackspace, Schneider Electric, Samsung, Siemens, Uber, Walmart, Warner Music, WebEx, and thousands of others (all in addition to the PostgreSQL community and ecosystem).
Amazon Timestream was first announced at AWS re:Invent November 2018, but its launch was delayed until September 2020. This is Amazon’s time-series database-as-a-service. Amazon Timestream not only shares a similar name to TimescaleDB, but also embraces SQL as its query language. Amazon Timestream customers include Autodesk, PubNub, and Trimble.
We compare TimescaleDB and Amazon Timestream across several dimensions:
- Insert and query performance
- Cost for equivalent workloads
- Backups, reliability, and tooling
- Query language, ecosystem, ease-of-use
- Clouds and regions supported
Below is a summary of our results. For those interested, we go into much more detail later in this post.
Insert Performance, Query Performance
Our results are striking. TimescaleDB outperformed Amazon Timestream 6,000x on inserts and 5-175x on queries, depending on the query type. In particular, there were workloads and query types easily supported by TimescaleDB that Amazon Timestream was unable to handle.


These results were so dramatic that we did not believe them at first, and we tried a variety of workloads and settings to ensure we weren’t missing anything.
We even posted on Reddit to see if others had been able to get better performance with Amazon Timestream. Although feedback was hard to find, we weren’t the only ones seeing these performance results, as evidenced by a similar benchmark by Crate.io.

After all of our attempts to achieve better Amazon Timestream performance, we were even more confused when we read a recent post on the AWS Database Blog that discusses achieving ingest speeds of three billion metrics/hour.
Although the details of how they ingested this scale of data aren’t completely clear, it appears that each “monitored host” sent individual metrics at various intervals directly to Amazon Timestream.
To achieve three billion metrics/hour in their test, four million hosts sent 26 metrics every two minutes, an average of 33,000 hosts reporting 866,667 metrics every second.
It’s certainly impressive to support 33,000 connections per second without issue, and this demonstrates one of the key advantages that Amazon presents with a serverless architecture like Timestream.
If you have an edge-based IoT system that pre-computes metrics on thousands of edge nodes before sending them, Amazon Timestream could simplify your data collection architecture.
However, as you’ll see, if you have a more traditional client-server data-collection architecture, or one using a more common streaming pipeline with database consumers, like Apache Kafka, TimescaleDB can import more than three million metrics per second from one client—and doesn’t need 33,000 clients.
Because performance benchmarking is complex, we share the details of our setup, configurations, and workload patterns later in this post, as well as instructions on how to reproduce them.
Cost for Equivalent Workloads
The stark difference in performance translates into a large cost differential as well.
To compare costs, we calculated the cost for our above insert and query workloads, which store one billion metrics in TimescaleDB and ~410 million metrics in Amazon Timestream (because we were unable to load the full one billion—more later in this post), and ran our suite of queries on top.
For the same workloads, we found that fully managed TimescaleDB is 154x cheaper than Amazon Timestream (224x cheaper if you’re self-managing TimescaleDB on a virtual machine) and inserted twice as many metrics.

We go into further details about the cost comparison later in this post.
Backups, Reliability, and Tooling
For reliability, the differences are also striking. In particular, backups, reliability, and tooling feel like an afterthought with Amazon Timestream.
In the 240-page development guide for Amazon Timestream, the words “recovery” and “restore” don’t appear at all, and the word “backup” appears only once to tell the developer that there is no backup mechanism.
Instead, you can “[...]write your own application using the Timestream SDK to query data and save it to the destination of your choice” (page 100). There isn’t a mechanism or support to DELETE or UPDATE existing data.
The only way to remove data is to drop the entire table. Furthermore, there is no way to recover a deleted table since it is an atomic action that cannot be recovered through any Amazon API or Console.
In contrast, TimescaleDB is built on PostgreSQL, which means it inherits the 25+ years of hard, careful engineering work that the entire PostgreSQL community has done to build a rock-solid database that supports millions of mission-critical applications worldwide.
When operating TimescaleDB, one inherits all of the battle-tested tools that exist in the PostgreSQL ecosystem: pg_dump/pg_restore and pg_basebackup for backup/restore, high-availability/failover tools like Patroni, load balancing tools for clustering reads like Pgpool/pgbouncer, etc. Since TimescaleDB looks and feels like PostgreSQL, there are minimal operational learning curves. TimescaleDB “just works,” as one would expect from PostgreSQL.
Query Language, Ecosystem, and Ease-Of-Use
We applaud Amazon Timestream’s decision to adopt SQL as their query language. Even if Amazon Timestream functions like a NoSQL database in many ways, opting for SQL as the query interface lowers developers’ barrier to entry—especially when compared to other databases like MongoDB and InfluxDB.
That said, because Amazon Timestream is not a relational database, it doesn’t support normalized datasets and JOINs across tables. Also, because Amazon Timestream enforces a specific narrow table model on your data, deriving value from your data relies heavily on CASE statements and Common Table Expressions (CTEs) when requesting multiple measurement values (defined by “measurement_name”), leading to some clunky queries (see example later in this post).
TimescaleDB, on the other hand, has fully embraced all parts of the SQL language from day one—and extended SQL with functions custom-built to simplify time-series analysis. TimescaleDB is also a relational database, allowing developers to store their metadata alongside their time-series data and JOIN across tables as necessary. Consequently, with TimescaleDB, new users have a minimal learning curve and are in full control when querying their data.
Full SQL means that TimescaleDB supports everything that SQL has to offer, including normalized datasets, cross-table JOINs, subqueries, stored procedures, and user-defined functions.
Supporting SQL also enables TimescaleDB to support everything in the SQL ecosystem, including Tableau, Looker, PowerBI, Apache Kafka, Apache Spark, Jupyter Notebooks, R, native libraries for every major programming language, and much more.
For example, if you already use Tableau to visualize data or Apache Spark for data processing, TimescaleDB can plug right into the existing infrastructure due to its compatible connectors. And, given its roots, TimescaleDB supports everything in the PostgreSQL ecosystem, including tools like EXPLAIN that help pinpoint why queries are slow and identify ways to improve performance.
By contrast, even though Amazon Timestream speaks a variant of SQL, it is “SQL-like,” not full SQL. Thus, tooling that normally works with SQL—e.g., the Tableau and Apache Spark examples cited above—are unable to utilize Amazon Timestream data unless that tool incorporates specific Amazon Timestream drivers and SQL-like dialect.
This means, for example, that the tooling you might normally use to help you improve query performance doesn’t currently support Amazon Timestream. And, unfortunately, the current Amazon Timestream UI doesn’t give us any clues about why queries might be performing poorly or ways to improve performance (e.g., via settings or query hints).
In short, if you use PostgreSQL and any tools or extensions with your applications, they will “just work” when connected to TimescaleDB. The same isn’t true for Amazon Timestream.
So, while adopting a SQL-like query language is a great start for Amazon Timestream, we found a lot to be desired for a true “easy” developer experience.
Cloud Offering
Amazon Timestream is only offered as a serverless cloud on Amazon Web Services. As of writing, it is available in three U.S. regions and one E.U. region.
Conversely, TimescaleDB can be run in your own infrastructure or fully managed through our cloud offering, which make TimescaleDB available on AWS in over 75 regions and many different possible region/storage/compute configurations.
With TimescaleDB, our goal is to give our customers their choice of cloud and the ability to choose the region closest to their customers and co-locate with their other workloads.

What We Like About Amazon Timestream
Despite the results of this comparison, we liked several things about Amazon Timestream.
The highest on the list is the simplicity of setting up a serverless offering. There aren’t any sizing decisions or knobs to tweak. Simply create a database, table, and then start sending data.
This brings up a second advantage of a serverless architecture: even if throughput isn’t ideal from a single client, the service appears to handle thousands of connections without issue. According to their documentation, Amazon Timestream will eventually add more resources to keep up additional ingest or query threads. This means that an application shouldn’t be limited by the resources of one particular server for reads or writes.
Like with other NoSQL databases, some may find the schemaless nature of Amazon Timestream appealing, especially when a project is just getting off the ground.
Although schemas become more necessary as workloads grow for performance and data validation reasons, one of the reasons databases like MongoDB have grown in popularity is that they don’t require the same upfront planning as more traditional SQL databases.
Lastly, SQL. It shouldn’t come as a surprise that we like SQL as an efficient interface for the data we need to examine. And, although Amazon Timestream lacks some support for standard SQL dialects, most users will find it pretty straightforward to start querying data (after they understand Amazon Timestream’s narrow table model).
But why is Amazon Timestream so expensive, slow, and underwhelming?
The reality is that Amazon Timestream, despite taking two years post-announcement to launch, still seems half-baked.
Why is Amazon Timestream so expensive, slow, and seemingly underdeveloped? We assume the reason is because of its underlying architecture.
Unlike other systems that we and others have benchmarked via the Time-Series Benchmark Suite (e.g., InfluxDB and MongoDB), Amazon Timestream is completely closed-source.
Based on our usage and experience with other Amazon services, we suspect that under the hood Amazon Timestream is backed by a combination of other Amazon services similar to Amazon ElastiCache, Athena, and S3. But because we cannot inspect the source code (and because Amazon does not make this sort of information public), this is just a guess.
By comparison, all of the source code for TimescaleDB is available for anyone to inspect. We built TimescaleDB on top of PostgreSQL, giving it a rock-solid foundation and large ecosystem, and then spent years adding advanced capabilities to increase performance, lower costs, and improve the developer experience.
These capabilities include auto-partitioning via hypertables and chunks, faster queries via continuous aggregates, lower costs via 94 %+ native compression, high-performance (10+ million inserts a second), and more.
We believe the real reason behind the difference between the two products is the companies building these products and how each approaches software development, community, and licensing. (And kind reader, this is where our bias may sneak in a little bit.)
Amazon vs. Timescale
The viability of our company, Timescale, is 100 % dependent on the quality of TimescaleDB. If we build a sub-par product, we cease to exist.
Amazon Timestream is just another of the 200+ services that Amazon is developing. Regardless of the quality of Amazon Timestream, that team will still be supported by the rest of Amazon’s business—and if the product gets shut down, that team will find homes elsewhere within the larger company.
One can see this difference in how the two companies approach the developer community. Without a doubt, Amazon Web Services is a leader in all things cloud computing. However, with its enormous catalog of cloud services, many originally derived from external open-source projects, Amazon’s attention is spread over hundreds of products.
Case in point, when Amazon Timestream was announced in 2018, there was strong interest in when it would be released and how it would perform. However, after a two-year delay, with no information from Amazon, many gave up on waiting for the product. When the product was finally released on September 30, 2020, there was very little fanfare from the community.
In contrast, Timescale develops its source code out in the open, and developers can reach us for help anytime directly via our Slack channel (which is staffed by our engineers), whether they are a paying customer or not. We’ve continued to invest in our community by making all our software available for free while also serving our customers with our hosted and fully managed cloud services.
Building a high-performance, cost-effective, reliable, and easy-to-use time-series database is a hard and increasingly business-critical problem. For us, building TimescaleDB into a best-in-class time-series developer experience is an existential requirement. Without it, we cease to exist. For Amazon, Amazon Timestream is just a checkbox, another service to list on their website.
When Amazon is forced to compete on product quality, all open-source companies have a shot at building great businesses
Amazon has a history of offering services that take advantage of the R&D efforts of others: for example, Amazon Elasticsearch Service, Amazon Managed Streaming for Apache Kafka, Amazon ElastiCache for Redis, and many others.
If Amazon wanted to launch a time-series database service that supported SQL, why did they build one from scratch and not just offer managed TimescaleDB?
Answer: our innovative licensing. The core of TimescaleDB is open-source, licensed under Apache 2. But advanced capabilities, such as compression and continuous aggregates, are licensed under the Timescale License, a source-available license that is open-source in spirit and makes all software available for free—but contains a critical restriction: preventing companies from offering that software via a hosted database-as-a-service.
The Timescale License is an example of a “Cloud Protection License,” which are licenses recognizing that the cloud has increasingly become the dominant form of open-source commercialization.
So these licenses protect the right of offering the software in the cloud for the main creator/maintainer of the project (who often contributes 99 % of the R&D effort). (Read more about how we're building a self-sustaining open-source business in the cloud era.)
This “cloud protection” prevents Amazon from just distributing our R&D and forces them to develop their own offering and compete on product quality, not just distribution. And as we can see from Amazon Timestream, building best-in-class database technologies is not easy, even for a company like Amazon.
The truth is that when Amazon is forced to compete on product quality, all open-source companies have a shot at building great businesses.
We welcome Amazon’s new entry to the time-series database market and appreciate that developers now have even more choices for storing and analyzing their time-series data. Competition is good for developers and helps drive further innovation.
For those who want to dig deeper into our benchmarking and comparison, we include detailed notes and methodology below.
For those who want to try Timescale, create a free account to get started with a fully managed TimescaleDB instance (100 % free for 30 days).
Want to host TimescaleDB yourself? Visit our GitHub to learn more about options, get installation instructions, and more (and, if you like what you see, ⭐️ are always appreciated!).
Join our Slack community to ask questions, get advice, and connect with other developers (I, as well as our co-founders, engineers, and passionate community members are active on all channels).
Performance Comparison Details
Here is a quantitative comparison of the two databases across insert and query workloads.
Note: We've released all the code and data used for the below benchmarks as part of the open-source Time Series Benchmark Suite (TSBS) (GitHub, announcement), so you can reproduce our results or run your own analysis.
Typically, when we conduct performance benchmarks (for example, in our previous benchmarks versus InfluxDB and MongoDB) we use five different dataset configurations. These configurations increase metric loads and cardinalities, to simulate a breadth of time-series workloads for inserts and queries.
However, as you’ll see below, because of performance issues with Amazon Timestream, we were unable to look at Amazon Timestream’s performance under higher cardinalities and were limited to testing just our lowest-cardinality dataset.
Machine Configuration
Amazon Timestream
Amazon Timestream is a serverless offering, which means that a user cannot provision a specific service tier. The only meaningful configuration option that a user can modify is the “memory store retention” period and the “magnetic store retention” period. In Amazon Timestream, data can only be inserted into a table if the timestamp falls within the memory store retention period. Therefore, the only setting that we modified to insert data for our first test was to set the memory store retention period to 865 hours (~36 days) to provide padding to account for a slower insert rate.
It did not take long for us to realize that Amazon Timestream’s insert performance was dramatically slower than other time-series databases we’ve benchmarked. Therefore, we took extra time to test insert performance using three different Amazon EC2 instance configurations, each launched in the same region as our Amazon Timestream database:
- t3.medium running Ubuntu 18 LTS, 2 vCPUs, 4 GB mem, up to 5 Gb network
- c5n.2xlarge running Ubuntu 20 LTS, 8 vCPUs, 29 GB mem, up to 25 Gb network
- m5n.12xlarge running Ubuntu 18 LTS, 48 vCPUs,192 GB mem, 50 Gb network
After numerous attempts to insert data with each of these instance types, we determined that the size of the client did not noticeably impact insert performance at all. Instead, we needed to run multiple client instances to ingest more data.
In the end, we chose to write data from 1 and 10 t3.medium clients, each running 20 threads of TSBS. In the case of 10 clients, each covered a portion of the 30 days to avoid writing duplicate data (Amazon Timestream does not support writing duplicate data).
TimescaleDB
To test the same insert and read latency performance on TimescaleDB, we used the following setup:
- Version: TimescaleDB version 1.7.4, with PostgreSQL 12
- One remote client machine and one database server, both in the same cloud data center
- Instance size: both client and database server ran on DigitalOcean virtual machines (droplets) with 32 vCPU and 192 GB memory each
- OS: both server and client machines ran Ubuntu 18.04.3
- Disk Size: 4.8 TB of disk in a raid0 configuration (EXT4 filesystem)
- Deployment method: TimescaleDB was deployed using Docker images from the official Docker hub

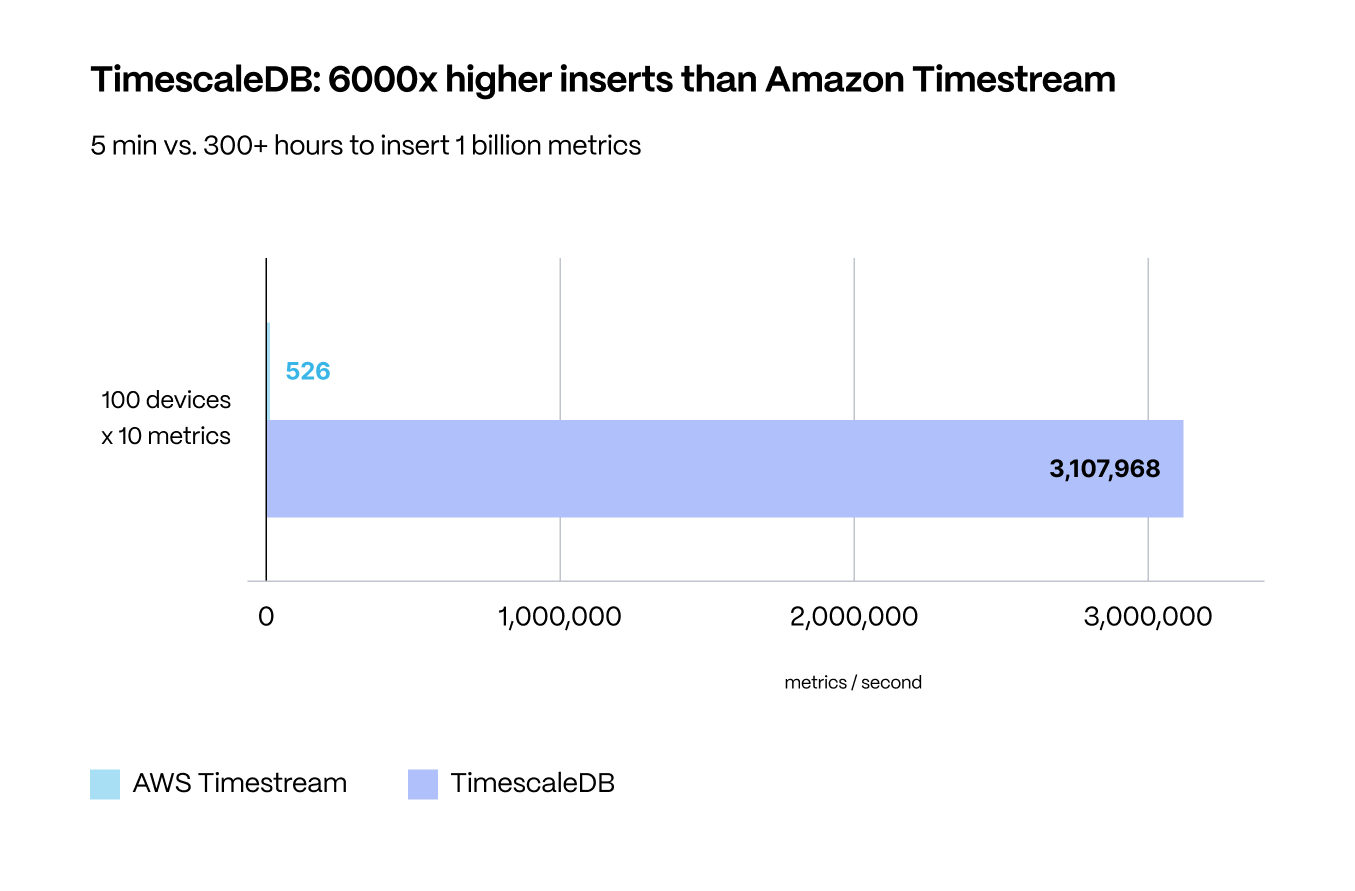
In our tests, TimescaleDB outperformed Amazon Timestream by a shocking 6,000x on inserts.
The lackluster insert performance of Amazon Timestream took us by surprise, especially since we were using the Amazon Timestream SDK and modeling our TSBS code from examples in their documentation.
In the interest of being thorough and fair to Amazon Timestream, we tried increasing the number of clients writing data, made some code modifications to increase concurrency (in ways that weren’t necessary for TimescaleDB), and worked to eliminate any possible thread contention, and then ran the same benchmark with 10 clients on Amazon Timestream.
After this effort, we were able to increase Amazon Timestream performance to 5,250 metrics/second (across 10 clients)—but even then, TimescaleDB (with only one client and without any extra code modifications) outperformed Amazon Timestream by 600x.
(Hypothetically, we could have started a lot more clients to increase insert performance on Amazon Timestream (assuming no bottlenecks), but with an average ingest rate of ~523 metrics/second per client, we would have had to start ~61,000 EC2 instances at the same time to finish inserting metrics as fast as one client writing to TimescaleDB.)
In particular, with this low performance, we were only able to test our lowest cardinality workload, not our usual five—even though we worked at it for more than a week. This scenario attempts to insert 100 simulated devices, each generating 10 CPU metrics every 10 seconds for ~100M reading intervals (for one billion metrics).
We never actually made it to the full one billion metrics with Amazon Timestream. After nearly 40 hours of inserting data from 10 EC2 clients, we were only able to insert slightly over 410 million metrics. (The dataset was created using Time-Series Benchmarking Suite, using the cpu-only use case.)
Let us put it another way:
- We first tested Amazon Timestream and TimescaleDB with one client writing data.
- Then, in an attempt to be fair to Amazon Timestream, we tested it with 10 separate EC2 instances over a two-day period, inserting batches of 1,000 readings (100 hosts, 10 measurements per host) as fast as possible.
- It’s also worth noting that most clients started to receive a fatal connection error from Amazon Timestream between the 28 and 32-hour mark and didn’t recover. Only one client made uninterrupted inserts for more than 40 hours before we manually stopped it. It’s possible that with some additional error checking with the Amazon Timestream SDK response, TSBS could have recovered on its own and continued to send metrics from all 10 clients.
In total, this means that we inserted data into Amazon Timestream for 332.5 hours and achieved slightly more than 410 million metrics.
TimescaleDB inserted one billion metrics from one client in just under five minutes.
Amazon claims that Amazon Timestream will learn from your insert and query patterns and automatically adjust resources to increase performance. Their documentation specifically warns that writes may become throttled, with the only remedy to keep inserting at the same (or higher) rate until Amazon Timestream adjusts.
However, in our experience, 332.5 hours of inserting data at a very consistent rate was not enough time for it to make this adjustment.
The issue of cardinality: One other side-effect of Amazon Timestream taking so long to ingest data: we couldn’t compare how it performs with higher cardinalities, which are common in time-series scenarios, where we need to ingest a relentless stream of metrics from devices, apps, customers, and beyond. (Read more about the role of cardinality in time series and how TimescaleDB solves it.)
We’ve shown in previous benchmarks that TimescaleDB actually sees better performance relative to other time-series databases as cardinality increases, with moderate drop off in terms of absolute insert rate. TimescaleDB surpasses many other popular time-series databases, like InfluxDB, in terms of insert performance for the configurations of 4,000, 100,000, 1 million, and 10 million devices.
But again, we were unable to test this given Amazon Timestream’s (lack of) performance.
Insert performance summary:
- TimescaleDB outperforms Amazon Timestream in raw numbers that we found hard to believe. However, despite our best efforts to optimize Amazon Timestream, TimescaleDB still outperformed Amazon Timestream by 6,000x (600x if using 10 clients on Amazon Timestream to TimescaleDB’s one).
- In the time it took us to make a pot of coffee, TimescaleDB inserted one billion metrics for a 31-day period. With Amazon Timestream, we got two nights' sleep and inserted less than half the metrics.
- That said, if your insert performance is far below these benchmarks (e.g., a few thousand metrics/second), then insert performance will not be your bottleneck.
Full results:

More information on database configuration for this test:
Batch size
From our research and community members’ feedback, we’ve found that larger batch sizes generally provide better insert performance. (It’s one of the reasons we created tools like Parallel COPY to help our users insert data in large batches concurrently).
In our benchmarking tests for TimescaleDB, the batch size was set to 10,000, something we’ve found works well for this kind of high throughput. The batch size, however, is completely configurable and often worth customizing based on your application requirements.
Amazon Timestream, on the other hand, has a fixed batch size limit of 100 values. This seems to require significantly more overhead and insert latency increases dramatically as the number of metrics we try to insert at one time increases. This is one of the first reasons we believe insert performance was so much slower with Amazon Timestream.
Additional database configurations
For TimescaleDB, we set the chunk time depending on the data volume, aiming for 7-16 chunks in total for each configuration (see our documentation for more on hypertables - "chunks").
With Amazon Timestream, there aren’t additional settings you can tweak to try and improve insert performance—at least not that we found, given the tools provided by Amazon.
As mentioned in the machine configuration section above, we had to set the memory store retention period equal to ~36 days to ensure we could get all of our data inserted before the magnetic store retention period kicked in.
Query Performance Comparison

Measuring query latency is complex. Unlike inserts, which primarily vary on cardinality size, the universe of possible queries is essentially infinite, especially with a language as powerful as SQL.
Often, the best way to benchmark read latency is to do it with the actual queries you plan to execute. For this case, we use a broad set of queries to mimic the most common time-series query patterns.
For benchmarking query performance, we decided to use a c5n.2xlarge EC2 instance to perform the queries with Amazon Timestream. Our hope was that having more memory and network throughput available to the query application would give Amazon Timestream a better chance. The client for TimescaleDB was unchanged.
Recall that we ran these queries on Amazon Timestream with a dataset that was 40 % that of the one we ran on TimescaleDB (410 million vs. one billion metrics), owing to the insert problems we had above.
Also, because we had to set the memory store retention period to ~36 days, all the data we queried was in the fastest storage available. These two advantages should have given Amazon Timestream a considerable edge.
That said, TimescaleDB still outperformed Amazon Timestream by 5x to 175x, depending on the query, with Amazon Timestream unable to finish several queries.
The results below are the average from 1,000 queries for each query type. Latencies in this chart are all shown as milliseconds, with an additional column showing the relative performance of TimescaleDB compared to Amazon Timestream.

Results by query type:
SIMPLE ROLLUPS
For simple rollups (i.e., groupbys), when aggregating one metric across a single host for 1 or 12 hours, or multiple metrics across one or multiple hosts (either for 1 hour or 12 hours), TimescaleDB significantly outperforms Amazon Timestream by 11x to 28x.
AGGREGATES
When calculating a simple aggregate for one device, TimescaleDB again outperforms Amazon Timestream by a considerable margin, returning results for each of 1,000 queries more than 19x faster.
DOUBLE ROLLUPS
For double rollups aggregating metrics by time and another dimension (e.g., GROUPBY time, deviceId), TimescaleDB again achieves significantly better performance, 5x to 12x.
THRESHOLDS
When selecting rows based on a threshold (CPU > 90 %), we see Amazon Timestream really begin to fall apart. Finding the last reading for one host greater than 90 % performs 170x better with TimescaleDB compared to Amazon Timestream. And the second variation of this query, trying to find the last reading greater than 90% for all 100 hosts (in the last 31 days), never finished in Amazon Timestream.
Again, to be fair and ensure our query was returning the data we expected, we did manually run one of these queries in the Amazon Timestream Query interface of the AWS Console. It would routinely finish in 30-40 seconds (which would still be 36x slower than TimescaleDB).
In addition, running 100 of these queries at a time with the benchmark suite appears to be too much for the query engine, and results for the first set of 100 queries didn’t complete after more than 10 minutes of waiting.
COMPLEX QUERIES
Likewise, for complex queries that go beyond rollups or thresholds, there is no comparison. TimescaleDB vastly outperforms Amazon Timestream, in most cases because Amazon Timestream never returned results for the first set of 100 queries. Just like the complex aggregate above that failed to return any results when queried in batches of 100, these complex queries never returned results with the benchmark client.
In each case, we attempted to run the queries multiple times, ensuring that no other clients or processes were inserting or accessing data. We also ran at least one of the queries manually in the AWS Console to verify that it worked and that we got the expected results. However, when running these kinds of queries in parallel, there seems to be a major issue with Amazon Timestream being able to satisfy the requests.
For these more complex queries that return results from Amazon Timestream, TimescaleDB provides real-time responses (e.g., 10-100s of milliseconds), while Amazon Timestream sees significant human-observable delays (seconds).
And remember, this dataset only had a cardinality of 100 hosts, the lowest cardinality we typically test with the Time-Series Benchmarking Suite, and we were unable to test higher cardinality datasets because of Amazon Timestream issues).
Notice that Timescale exhibits 48x-175x the performance of Amazon Timestream on these complex queries, many of which are common to historical time-series analysis and monitoring.
Read latency performance summary
- For simple queries, TimescaleDB outperforms Amazon Timestream in every category.
- When selecting rows based on a threshold, TimescaleDB outperforms Amazon Timestream by a significant margin, being over 175x faster.
- For complex queries with even low cardinality, Amazon Timestream was unable to return results for sets of 100 queries within the 60-second default query timeout.
- Concurrent query load over the same time range seems to impact Amazon Timestream in a dramatic way.
Cost Comparison Details

These performance differences between TimescaleDB and Amazon Timestream lead to massive cost differences for the same workloads.
To compare costs, we calculated the cost for our above insert and query workloads, which store one billion metrics in TimescaleDB and ~410 million metrics in Amazon Timestream (because we could not load the full one billion), and run our suite of queries on top.
Pricing for Amazon Timestream is rather complex. In all, our bill for testing Amazon Timestream over the course of seven days cost us $336.39, which does not include any Amazon EC2 charges (which we needed for the extra clients). During that time, our bill shows that:
- We inserted 100 GB of data (~500 million metrics total across all of our attempts to ingest data)
- Stored a lot of data in memory (and we continue to be charged per hour for that data)
- Queried 21 TB of data when running 25,000 real-world queries
For comparison, our tests for TimescaleDB (inserts and queries) completed in far less than an hour, and our Digital Ocean droplet costs $1.50/hour. We also ran this test on Timescale, our fully managed TimescaleDB service, and it was also completed in far less than an hour, and the instance (8 vCPU, 32 GB, 1 TB) cost $2.18/hour.

$336.39 for Amazon Timestream vs. $2.18 for fully managed TimescaleDB ($1.50 if you would rather self-manage the instance yourself), which means that TimescaleDB is 154x cheaper than Amazon Timestream (224x cheaper if self-managed)—and it loaded and queried over twice the number of metrics.
Now, let’s dig a little deeper into our Amazon Timestream bill
When using Amazon Timestream, users are charged for usage in four main categories: data ingested, data stored in both memory and magnetic storage and the amount of data scanned to satisfy your queries.
Data that resides in the memory store costs $0.036 GB/hour, while data that is eventually moved to magnetic storage costs only $0.03 GB/month. For our one-month memory store setting (which was required to insert 30 days of historical data), that’s more than a 720x difference in cost for the same data.
What’s more, since Amazon Timestream doesn’t expose any information about how data is stored in the Console or otherwise, we have no idea how well-compressed this data is, or if there is anything more we could do to reduce storage.
The real surprise, however, came with querying data because the charges don’t scale with performance. Instead, you will be charged for the amount of data scanned to produce a query result, no matter how fast that result comes back. In almost all other database-as-a-service offerings, you can modify the storage, compute, or cluster size (at a known cost) for better performance.
After waiting nearly two days to insert 410 million metrics, we created the traditional set of query batches (as outlined above) and began to run our queries.
In total, we had 15 query files, each with 1,000 queries, for a total of 15,000 queries to run against both Amazon Timestream and TimescaleDB.
While some of the queries are certainly complex, others just ask for the most recent point for each host (and remember, this dataset only had 100 hosts). Also, recall from our query performance comparison that a few of the most complex queries were unable to return results for just 100 queries, let alone the full 1,000 query test.
With Amazon Timestream, you are still charged for the data that was read, even if the query was ultimately canceled or never returned a result.
To validate results, we ran each query file twice. In the case where three of the query files failed to return results, we attempted to execute them five times, hoping for some result.
Doing the math, this means that we ran around 25,000 queries. In doing so, Amazon says that we scanned 21,598.02 GB of data, which cost $215.98. There were certainly a few other ad hoc queries performed through the AWS Console UI, but before we started running the benchmarking queries, the total cost for scanning data was about $15.00.
Furthermore, as we’ve mentioned a few times, there is no built-in support to help you identify which queries are scanning too much data and how you might improve them. For comparison, both Amazon Redshift and Amazon RDS provide this kind of feedback in their AWS Console interface.
When we consider some of the recent user applications that we have highlighted elsewhere on our blog, like FlightAware or clevabit, 25,000 queries of various shapes and sizes would easily be run in a few hours or less.
While the bytes scanned might improve over time as partitioning improves, if you don’t need to scale storage beyond a few petabytes of data, it’s hard to see how this would be less costly than a fixed Compute and Storage cost.
Reliability Comparison Details
Another cardinal rule for a database: it cannot lose or corrupt your data. In this respect, the serverless nature of Amazon Timestream requires that you trust Amazon will not lose your data and all of the data will be stored without corruption. Usually, this is probably a pretty safe bet. In fact, many companies rely on services like Amazon S3 or Amazon Glacier to store their data as a reliable backup solution.
The problem is that we don’t know where our time-series data is stored in Amazon Timestream—because Amazon does not tell us.
This presents a specific challenge that Amazon hasn’t addressed natively: validating or backing up your data.
In their 240-page development guide, the words “recovery” and “restore” don’t appear at all, and the word “backup” appears only once to tell the developer that there isn’t a backup mechanism. Instead, you can “write your own application using the Timestream SDK to query data and save it to the destination of your choice” (page 100).
This is not to say that Amazon Timestream will lose or corrupt your data. As we mentioned, Amazon S3, for instance, is a widely known and used service for data storage. The issue here is that we’re unable to learn or easily verify where our data resides and how it’s protected in a service interruption.
We also found it worrisome that with Amazon Timestream, there isn’t a mechanism or support to DELETE or UPDATE existing data. The only way to remove data is to drop the entire table. Furthermore, there is no way to recover a deleted table since it is an atomic action that cannot be recovered through any Amazon API or Console.
Even if one were to write their own backup and restore utility, there is no method for importing more than the most recent year of data because of the memory store retention period limitation.
As an Amazon Timestream user, all these limitations put us in a precarious position. There’s no easy way to back up our data or restore it once we’ve accumulated more than a year's worth. Even if Amazon never loses our data, deleting an essential table of data through human error is not uncommon.
TimescaleDB uses a dramatically different design principle: build on PostgreSQL. As noted previously, this allows TimescaleDB to inherit over 25 years of dedicated engineering effort that the entire PostgreSQL community has done to build a rock-solid database that supports millions of applications worldwide. (In fact, this principle was at the core of our initial TimescaleDB launch announcement.)
Query Language, Ecosystem, and Ease-Of-Use Comparison Details
We applaud Amazon Timestream’s decision to adopt SQL as their query language. We have always been big fans and vocal advocates of SQL, which has become the query language of choice for data infrastructure, is well-documented, and currently ranks as the third-most commonly used programming language among developers (see our SQL vs. NoSQL comparison for more details).
Even if Amazon Timestream functions like a NoSQL database in many ways, opting for SQL as the query interface lowers developers’ barrier to entry—especially when compared to other databases like MongoDB and InfluxDB with their proprietary query languages.

As discussed earlier in this article, Amazon Timestream is not a relational database, despite feeling like it could be because of the SQL query interface. It doesn’t support normalized datasets, JOINs across tables, or even some common “tricks of the trade” like a simple LATERAL JOIN and correlated subqueries.
Between these SQL limitations and the narrow table model that Amazon Timestream enforces on your data, writing efficient (and easily readable) queries can be a challenge.
Example
To see a brief example of how Amazon Timestream’s “narrow” table model impacts the SQL that you write, let’s look at an example given in the Timestream documentation, Queries with aggregate functions.
Specifically, we’ll look at the example to “find the average load and max speed for each truck for the past week”:
Amazon Timestream SQL (CASE statement needed)
SELECT
bin(time, 1d) as binned_time,
fleet,
truck_id,
make,
model,
AVG(
CASE WHEN measure_name = 'load' THEN measure_value::double ELSE NULL END
) AS avg_load_tons,
MAX(
CASE WHEN measure_name = 'speed' THEN measure_value::double ELSE NULL END
) AS max_speed_mph
FROM "sampleDB".IoT
WHERE time >= ago(7d)
AND measure_name IN ('load', 'speed')
GROUP BY fleet, truck_id, make, model, bin(time, 1d)
ORDER BY truck_idTimescaleDB SQL
SELECT
time_bucket(time, '1 day') as binned_time,
fleet,
truck_id,
make,
model,
AVG(load) AS avg_load_tons,
MAX(speed) AS max_speed_mph
FROM "public".IoT
WHERE time >= now() - INTERVAL '7 days'
GROUP BY fleet, truck_id, make, model, binned_time
ORDER BY truck_idIf the above is any indication, even the most simple aggregate queries in Amazon Timestream require multiple levels of CASE statements and column renaming. We were unable to write this query or pivot the results more easily.
Conversely, as evidenced in the above example, with TimescaleDB, we use standard SQL syntax. Additionally, any query that already works with your PostgreSQL-supported applications will “just work.” The same isn’t true for Amazon Timestream.
So while the decision to adopt a SQL-like query language is a great start for Amazon Timestream, there is still a lot to be desired for a truly frictionless, developer-first experience.
Summary
No one wants to invest in a technology only to have it limit their growth or scale in the future, let alone invest in something that's the wrong fit today.
Before making a decision, we recommend taking a step back and analyzing your stack, your team's skills, and your needs (now and in the future). It could be the difference between infrastructure that evolves and grows with you and one that forces you to start all over.
In this post, we performed a detailed comparison of TimescaleDB and Amazon Timestream. We don’t claim to be Amazon Timestream experts, so we’re open to suggestions on improving this comparison—and invite you to perform your own and share your results.
In general, we aim to be as transparent as possible about our data models, methodologies, and analysis, and we welcome feedback. We also encourage readers to raise any concerns about the information we’ve presented to help us with benchmarking in the future.
We recognize that Timescale isn’t the only time-series solution on the market. There are situations where it might not be the best time-series database choice, and we strive to be upfront in admitting where an alternate solution may be preferable.
We’re always interested in holistically evaluating our solution against others, and we’ll continue to share our insights with the greater community.
Want to Learn More About Timescale?
Create a free account to get started with a fully managed TimescaleDB instance (100 % free for 30 days).
Want to host TimescaleDB yourself? Visit our GitHub to learn more about options, get installation instructions, and more (and, as always, ⭐️ are appreciated!)
Join our Slack community to ask questions, get advice, and connect with other developers (I, as well as our co-founders, engineers, and passionate community members are active on all channels).


