How to Store and Analyze NFT Data in a Relational Database

In this post, we share behind-the-scenes technical insights about how we designed and built the Timescale NFT Starter Kit. We discuss the technical thought process behind how we selected a reliable source of NFT data, how we designed a database schema to ingest and analyze NFT sales data, and how we handled some of the challenges behind data ingestion and analysis in our quest to explore the NFT world from a data-driven perspective.
We recently launched the Timescale NFT Starter Kit, a step-by-step guide to get up and running with collecting, storing, and analyzing NFT data. Our goal was to help developers who are crypto-enthusiasts (or just crypto-curious) bring data to their NFT purchasing decisions, build more complex NFT tracking projects or just learn about the space from a more data-driven perspective (see our announcement blog for more details).
The Timescale NFT Starter Kit consists of:
- A database schema to efficiently store and query data.
- SQL queries to use as a starting point for your own analysis.
- Pre-built dashboards and templates in popular data visualization tools like Apache Superset and Grafana for visualizing your data analysis.
- A Python script to collect real-time data from OpenSea, as well as a sample dataset to play around with.
- A tutorial that takes you step-by-step.
The project received a lot of love on Twitter and the 20 Time Travel Tiger NFTs, which we created to reward the developers who completed the NFT Analysis tutorial first, were all claimed within 14 days of us publishing the NFT Starter Kit. Even though all the Time Travel Tiger NFTs were claimed, the NFT Analysis Tutorial is still available for you to complete and is a great starting point for getting started with NFT data and unearthing insights from it (it’s a fun weekend project!).
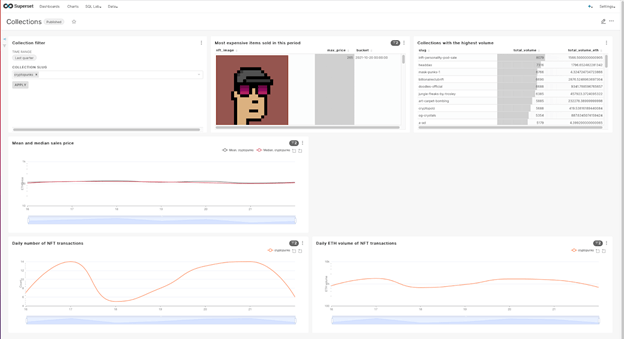
In addition to the tutorial, we created pre-built dashboards which enable you to start exploring NFT trends in less than 5 minutes using popular visualization tools Apache Superset and Grafana. See our demo videos for a walk-through of installing and using the pre-built dashboards.

Given the growth of the NFT space, with companies like OpenSea reaching billion dollar valuations and the launch of new marketplaces like LooksRare, there is growing developer interest in collecting and analyzing NFT data. To help fellow developers who are interested in NFT data, we want to share the technical thought process behind how we designed and built the Timescale NFT Starter Kit.
In the rest of this post, we’ll discuss the core decisions behind the following aspects of the Timescale NFT Starter Kit:
- Selecting a data source
- Selecting data to analyze
- Designing a database schema
- Formulating SQL queries for analysis
We’re openly sharing our experience working with NFT data in the hopes that it benefits other developers who are building projects around collecting, storing, and analyzing NFT data. The NFT space is relatively new and so we hope this inspires other developers working with NFT data to publicly share their experience and knowledge for the betterment of the community as a whole.
Let’s begin by discussing how we selected a source of NFT data…
Selecting a data source
There were a few considerations that went into choosing the best NFT data API for the NFT Starter Kit:
- It needs to be freely available (so everybody can try it for free).
- It needs to provide a diverse set of data points from the NFT ecosystem (to provide a lot of ways to analyze the data).
- The API server should be reliable in terms of uptime and data quality.
OpenSea (and its NFT API), being the largest and one of the first NFT marketplaces, proved to be a great choice for the NFT Starter Kit because it meets all three requirements.
About the OpenSea API
The OpenSea API provides access to quite a few data fields about assets, accounts, events, and more. Initially when we released the NFT Starter Kit, the OpenSea API didn’t require an API key to use it. Since then, the API does require a key but you can easily request one from their website.
The OpenSea API is capable of returning data about events that happened outside the OpenSea platform. This feature enables you to analyze the broader market as well if you want to.
Using this API, you can fetch historical and real-time data as well. To be nice to the servers, in the ingestion script we provide, there’s a 2 second delay between requests by default to comfortably fetch historical data from the past 2 years but still relatively fast.
It’s also possible to configure the NFT Starter Kit ingestion script to fetch the most recent data from the past 1 min/hour/day depending on your needs. You just need to modify the time window accordingly in the config file in the GitHub repo.
Making sense of the API and data fields
At the time of creating the NFT Starter Kit (October 2021), the OpenSea documentation felt incomplete. We didn’t get much information from the docs about the data fields we should expect back from the API, or what data type we should use to store those values. But we were still able to explore and learn about the data fields just by experimenting with the API.
Most of the data fields were self-explanatory and didn’t require modification before ingesting. There was one field though which was harder to understand for someone new to the crypto space: total_price. One important piece of information which wasn’t documented in the OpenSea API is that the total_price value, that was included in each sale event response, should be interpreted as Wei and not ether. This is important because 1 ETH = 1018 Wei. Wei is like satoshi to bitcoin or pennies to the dollar. Hence this value:
"total_price": "145000000000000000"
…is not 145000000000000000 ETH but instead 0.145 ETH. So we needed to convert this value from Wei to ETH before each insert.
OpenSea API Python wrapper library
We also looked for some API wrapper libraries which are usually already available for popular APIs, but we didn’t find any which covered the /events endpoint. Since encountering this problem, I created and open sourced an OpenSea API Python wrapper which covers all the GET endpoints and makes it easy to fetch NFT data from OpenSea in Python.
In general, the OpenSea API is fairly intuitive with a great mechanism for making requests, applying query parameters, and pagination. It also displays explicit error messages in case you do something wrong. The documentation has been improved since we created the NFT Starter Kit, especially as they added new pages for each data type recently - namely assets, collection, events, and account - that give a brief description of each data field.
Next, let’s see how we narrowed our focus to make it easier to ingest NFT data and which endpoints give us relevant time-series data.
Focusing on NFT sales data
As the OpenSea API has multiple interesting endpoints that can provide NFT data, there are many possible ways one could go about analyzing NFTs. From the beginning, we were certain that we wanted to focus on the time-series aspect of the data. Time-series data allows you to analyze NFT trends over time per individual NFT or project for example. Hence, it was natural to use the /events endpoint because that endpoint provides data about NFT transactions with timestamps.

For a beginner, the complex JSON responses containing loads of data fields provided by this endpoint might be overwhelming at first, so we decided to only focus on successful sale transactions and ignore offers and other types of events. This also made our schema and data analysis focus more on NFT sales.
Focusing on sales data simplified our schema a lot because this way we could freely ignore fields only available for offers (e.g., bid amount) which would have made us create more tables or make the hypertable more complex.
Luckily, the OpenSea API also includes some data fields from other endpoints in the event response. Which means you can fetch not just the event data itself but also additional data about the asset, the collection, and the accounts that participated in the event. So basically the /events endpoint can return four different types of NFT data: asset, collection, accounts (that participated in the sale), and the transaction itself. This allows you to use only one endpoint but still be able to fetch a diverse set of data fields.
In order to ingest only successful sale transactions we used the event_type OpenSea API URL query parameter and set it to “successful”. This was an important filter because when we started to backfill the data, without any restrictions on event type, we realized that most of the event data were offers and not sales. We decided to ignore offers data (for now!) and only focus on sales.
If you are interested in not just sale transactions, but other events as well feel free to use the NFT Starter Kit as a starting point and modify it. You can use our tutorial to get started and then modify the ingest script and schema to ingest not just sales but offers and other event types too so you can analyze those events as well.
Next, let’s see how we came up with the final schema design for sales events.
Designing an NFT sales schema
Going through the process of designing a schema can provide a lot of value. Thinking about your schema allows you to start with the questions you want to ask, plan relationships between the data fields, and also formulate the queries you will want to run. It makes you think about what it is that you want to get out of the database. And that’s a very useful step to understanding your data better, even before starting ingesting.
In the long run, it might be worthwhile to spend more time at the beginning to design the proper schema so it will be much easier to write efficient queries later on using the relationships and logical connections you determine with the initial schema design.
At a high-level, our NFT sales schema needed to achieve three things:
- It should provide an easy way to query the time-series data and
JOINit with relational tables that store additional information (be able to query information about assets and collections (eg. name, link, etc) easily from the time-series table) - Have some level of normalization, including foreign keys where necessary
- Leave room for future changes regarding what fields we want to analyze deeper (storing “not that interesting” fields in a JSONB column)
We tried to come up with a schema that allowed us to make efficient queries involving data fields we found interesting at the time. Other fields still needed to be available but it was okay to store them in a JSONB field.
When working with NFT data, if you are not already an NFT and blockchain domain expert, you might not understand what some of the data fields mean. Nonetheless, with some time spent on researching the topic, you can get a decent amount of knowledge to understand the basics. For example, you only have bid_amount value for an event if it was an offer and in case of a sale event you have a total_price field instead, or that in a sale transaction the winner_account is the one that bought the NFT or there can only be three types of auction, etc.
Another aspect is that you need to know what fields need to be (or can be) UNIQUE. For example, collection_slug is unique, there are no two collections with the same slug. But collection_name is not unique.
Once you’ve created the correct schema that fits both the domain and your query needs, you can create additional indexes on certain columns.
What columns should have indexes? Generally, you should put indexes on columns which you will use in WHERE and INNER JOIN clauses. Basically, if you will filter a lot on certain columns you should consider creating an index on those. But be aware that indexes take up space and make inserting data slower as well.
Due to OpenSea's lack of detailed field-level documentation (which they improved since the creation of the NFT Starter Kit), we relied on our hands-on experiments using the API and the JSON responses we received, to get a deeper understanding of the different data fields and explore edge cases.
Let’s have a look at a snippet from a sample API response:
[
{
"approved_account": null,
"asset": {
"id": 84852466,
"image_url": "https://lh3.googleusercontent.com/...",
"name": "Kangaroo Kingz #41",
"description": null,
"asset_contract": {...},
"permalink": "https://opensea.io/assets...",
"collection": {
"description": "Come join the Kangaroo Kingz and lets bounce to the moon...",
"name": "Kangaroo Kingz"
},
"owner": {...}
},
"collection_slug": "kangaroo-kingz",
"created_date": "2021-11-09T07:57:36.108433",
"event_type": "successful",
"id": 1771735968,
"quantity": "1",
"seller": {...},
"total_price": "1600000000000000",
"transaction": {...},
"winner_account": {...}
}
]
As you can see, we have a lot of interesting data fields in this snippet. One benefit of this kind of response is that it has information not just about the event itself (eg. event_type, quantity, total price) but also other things like asset, collection, and accounts. Because of this, you don’t need to make separate requests to fetch additional data, everything is already in this one response.
On the other hand, it makes it a little harder to cherry-pick what data fields you really need from this deeply nested JSON object. If you want to generate an example JSON yourself, you can do that in the OpenSea docs.
The OpenSea API allows up to 300 items to be included in one response. This allows for faster fetching and ingesting because you can do batches of 300 rather than one-by-one.
Storing NFT time-series data in a relational database
TimescaleDB is a relational time-series database built atop PostgreSQL. It supports full-SQL and you can also JOIN your time-series tables with other regular PostgreSQL tables while having access to time-series specific features.


Table definitions and indexes
When designing a schema that involves time-series data, it’s essential to identify early on which table will store the time-series data. This is important because if you use TimescaleDB that table will need to be converted to a hypertable so it can leverage the underlying TimescaleDB time-based partitioning.
You also need to see where it makes sense to use indexes. In general, you want to create indexes on columns that will be often used in WHERE and JOIN clauses. In the case of our NFT Starter Kit tutorial we decided to put the create index on asset_id, collection_id, and payment_symbol columns to speed up queries where those columns are involved in the filtering. Optionally, you might also want to put an index on one of the account columns. For example, if you often want to filter by winner accounts in your queries it might be worthwhile to create an index on winner_account. Depends on what you want to focus on in your queries.
Note that TimescaleDB hypertables have an index on the time column by default when you create the hypertable, so you don’t need to manually create them.
Finally, this became our schema to store NFT sales data:
/* NFT Starter Kit schema definition */
CREATE TABLE collections (
id BIGINT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
slug TEXT UNIQUE,
name TEXT,
url TEXT,
details JSONB
);
CREATE TABLE accounts (
id BIGINT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
user_name TEXT,
address TEXT UNIQUE NOT NULL,
details JSONB
);
CREATE TABLE assets (
id BIGINT PRIMARY KEY,
name TEXT,
collection_id BIGINT REFERENCES collections (id), -- collection
description TEXT,
contract_date TIMESTAMP WITH TIME ZONE,
url TEXT UNIQUE,
img_url TEXT,
owner_id BIGINT REFERENCES accounts (id), -- account
details JSONB
);
CREATE TYPE auction AS ENUM ('dutch', 'english', 'min_price');
CREATE TABLE nft_sales (
id BIGINT,
"time" TIMESTAMP WITH TIME ZONE,
asset_id BIGINT REFERENCES assets (id), -- asset
collection_id BIGINT REFERENCES collections (id), -- collection
auction_type auction,
contract_address TEXT,
quantity NUMERIC,
payment_symbol TEXT,
total_price DOUBLE PRECISION,
seller_account BIGINT REFERENCES accounts (id), -- account
from_account BIGINT REFERENCES accounts (id), -- account
to_account BIGINT REFERENCES accounts (id), -- account
winner_account BIGINT REFERENCES accounts (id), -- account
CONSTRAINT id_time_unique UNIQUE (id, time)
);
SELECT create_hypertable('nft_sales', 'time');
CREATE INDEX idx_asset_id ON nft_sales (asset_id);
CREATE INDEX idx_collection_id ON nft_sales (collection_id);
CREATE INDEX idx_payment_symbol ON nft_sales (payment_symbol);
CREATE INDEX idx_winner_account ON nft_sales (winner_account);
Here’s a sample from the nft_sales table:
| id | time | asset_id | collection_id | auction_type | contract_address | quantity | payment_symbol | total_price | seller_account | from_account | to_account | winner_account |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1161790724 | 2021-09-29 11:28:59 | 4985850 | 203 | dutch | 0xb1690c08e213a35ed9bab7b318de14420fb57d8c | 1 | ETH | 0.004985511081037315 | 118036 | 3658 | 4708321 | 4708321 |
| 1168642424 | 2021-09-29 22:36:14 | 5075728 | 203 | dutch | 0xb1690c08e213a35ed9bab7b318de14420fb57d8c | 1 | ETH | 0.006524209857283181 | 118036 | 3658 | 4511308 | 4511308 |
| 653312019 | 2021-08-27 03:09:40 | 130356 | 203 | dutch | 0xb1690c08e213a35ed9bab7b318de14420fb57d8c | 1 | ETH | 0.005 | 16266029 | 3658 | 2164288 | 2164288 |
| 924559657 | 2021-09-16 12:04:48 | 51793473 | 21625 | dutch | 0xb6dae651468e9593e4581705a09c10a76ac1e0c8 | 1 | ETH | 0.4 | 9863090 | 3040 | 3040 | |
| 1310420636 | 2021-10-10 12:13:01 | 626022 | 203 | dutch | 0xb1690c08e213a35ed9bab7b318de14420fb57d8c | 1 | ETH | 0.005 | 325215 | 3658 | 12859 | 12859 |
NFTs traded in extreme quantities
In the initial version of the schema, we used BIGINT for the quantity field. Then when we first started ingesting data to test the schema everything looked fine. After a couple tens of thousands of inserted records later we started to get some error messages, like this:
psycopg2.errors.NumericValueOutOfRange: value “10000000000000000000” is out of range for type bigint
The data field that caused this issue was the “quantity” field. Unexpectedly there were some NFTs that were traded in extremely high quantities and the value didn’t fit in the BIGINT data type. So we ended up using the NUMERIC PostgreSQL data type which proved to be sufficient. In PostgreSQL numeric and decimal data types are the same, they leave room for up to 131072 digits before the decimal point and up to 16383 digits after the decimal point.
Example queries
Let’s look at some example queries from the NFT Starter Kit tutorial.
Look up a specific account’s purchase history from the past 3 months
/* Snoop Dogg's purchases in the past 3 months aggregated */
WITH snoop_dogg AS (
SELECT id FROM accounts
WHERE address = '0xce90a7949bb78892f159f428d0dc23a8e3584d75'
)
SELECT
COUNT(*) AS trade_count,
COUNT(DISTINCT asset_id) AS nft_count,
COUNT(DISTINCT collection_id) AS collection_count,
COUNT(*) FILTER (WHERE winner_account = (SELECT id FROM snoop_dogg)) AS buy_count,
SUM(total_price) AS total_volume_eth,
AVG(total_price) AS avg_price,
MIN(total_price) AS min_price,
MAX(total_price) AS max_price
FROM nft_sales
WHERE payment_symbol = 'ETH' AND winner_account = (SELECT id FROM snoop_dogg)
AND time > NOW()-INTERVAL '3 months'
trade_count|nft_count|collection_count|buy_count|total_volume_eth |avg_price |min_price|max_price|
-----------+---------+----------------+---------+------------------+------------------+---------+---------+
58| 57| 20| 58|1825.5040000000006|31.474206896551735| 0.0| 1300.0|
This query uses the nft_sales hypertable to return aggregations based on records that involve one specific buyer account (in this example we use Snoop Dogg’s account). The query uses the indexes that we created on winner_account and payment_symbol.
Top 5 most expensive NFTs in the CryptoKitties collection
/* Top 5 most expensive NFTs in the CryptoKitties collection */
SELECT a.name AS nft, total_price, time, a.url FROM nft_sales s
INNER JOIN collections c ON c.id = s.collection_id
INNER JOIN assets a ON a.id = s.asset_id
WHERE slug = 'cryptokitties' AND payment_symbol = 'ETH'
ORDER BY total_price DESC
LIMIT 5
nft |total_price|time |url |
---------------+-----------+-------------------+-----------------------------------------------------------------------+
Founder Cat #40| 225.0|2021-09-03 14:59:16|https://opensea.io/assets/0x06012c8cf97bead5deae237070f9587f8e7a266d/40|
Founder Cat #17| 177.0|2021-09-03 01:58:13|https://opensea.io/assets/0x06012c8cf97bead5deae237070f9587f8e7a266d/17|
润龙🐱👓创世猫王44# | 150.0|2021-09-03 02:01:11|https://opensea.io/assets/0x06012c8cf97bead5deae237070f9587f8e7a266d/44|
grey | 149.0|2021-09-03 02:32:26|https://opensea.io/assets/0x06012c8cf97bead5deae237070f9587f8e7a266d/16|
Founder Cat #38| 148.0|2021-09-03 01:58:13|https://opensea.io/assets/0x06012c8cf97bead5deae237070f9587f8e7a266d/38|
This query filters the nft_sales table by collection slug and JOINs both the collections and assets table. The query also uses the indexes that we created on collection_id, payment_symbol, and collections.slug.
For more queries check out the GitHub repository, or watch the recording of our live stream where you can see the database in action.
Resources and learn more
We hope you found this blog post useful! If you’re interested in trying out the NFT Starter Kit you can do so by cloning our repository on Github. We also suggest following the NFT Analysis tutorial in our docs which walks you through how to ingest NFT data and also how to analyze it using PostgreSQL and TimescaleDB.
The easiest way to store and analyze NFT data (and complete the NFT Starter Kit tutorial!) is using a fully-managed database on Timescale. Sign up here - it’s 100% free for 30-days, no credit card required.
👉 Complete the NFT tutorial with Timescale - no credit card required.
Sign up for free
If you prefer managing your own database, you can install and use TimescaleDB for free.
Furthermore, you can learn more about using TimescaleDB for NFT and other crypto use cases by watching the recordings of the Stocks & Crypto SQL Show (join us live on Twitch).
If you have questions about the NFT Starter Kit or TimescaleDB in general, join our 8,000+ member Slack community, and get help from the Timescale Team and users. You can also tweet your projects and questions to us @TimescaleDB and use the hashtag #TimescaleNFTs.
Finally, if you are interested in getting a lot more involved with Timescale and NFT data, we are hiring worldwide!



