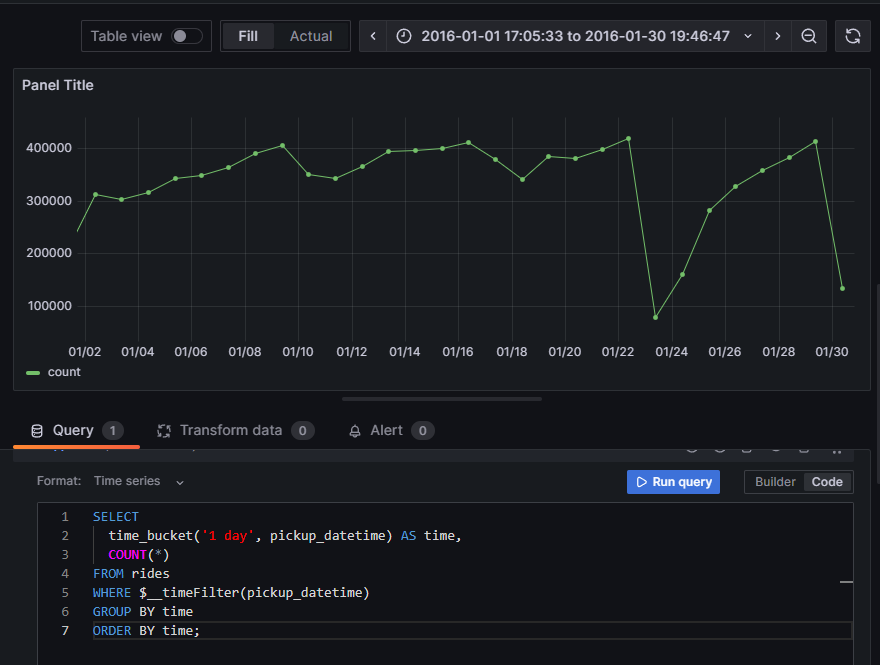
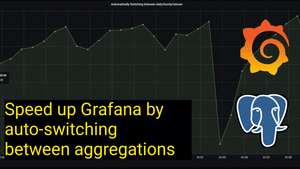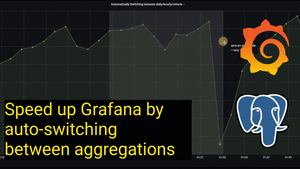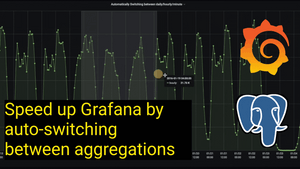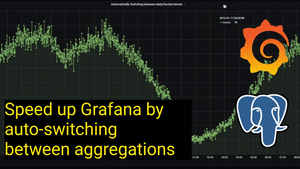
![Grafana 101: Interactivity, Templating, and Sharing [Recap]](/blog/content/images/size/w300/2020/06/Screen-Shot-2020-06-10-at-11.06.05-AM.png)
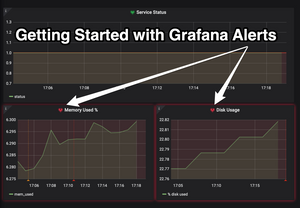
![Grafana 101: Getting Started with Alerting [Recap]](/blog/content/images/size/w300/2020/06/GrafanaAlertsBlogCover.png)
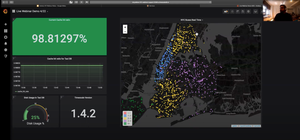
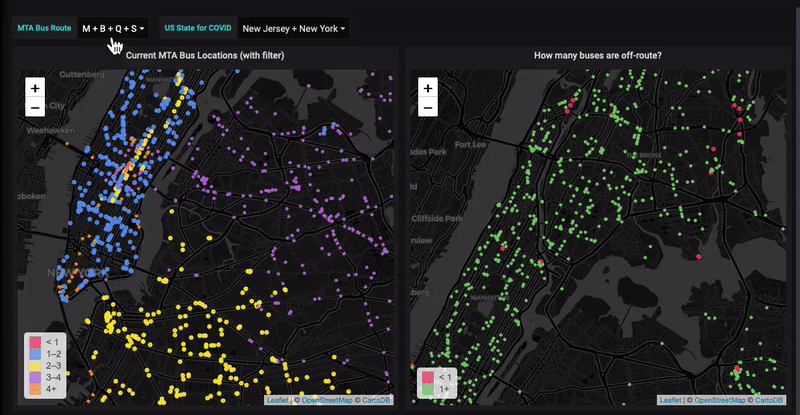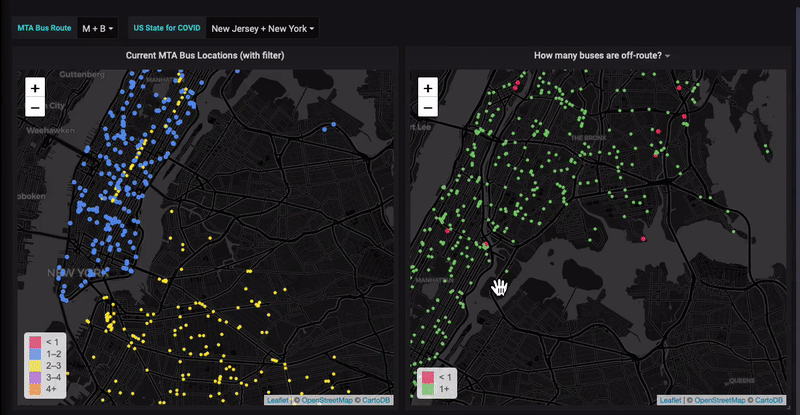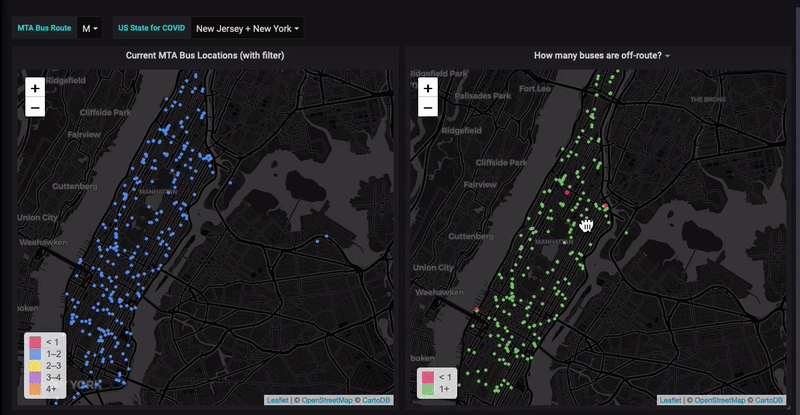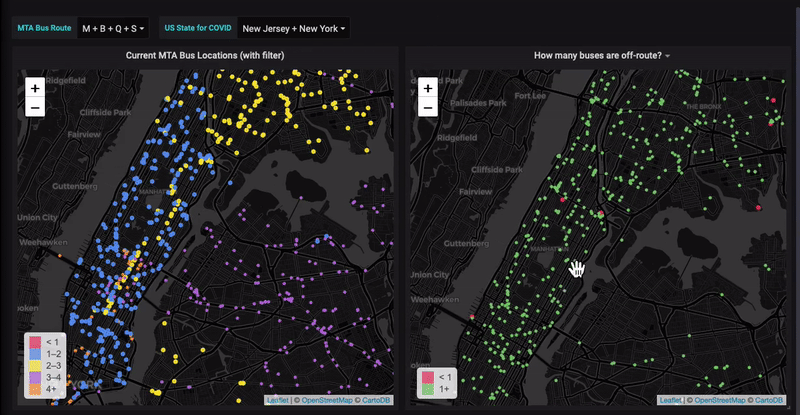

![[New Webinar]: How to analyze your Prometheus data in SQL: 3 queries you need to know](/blog/content/images/size/w300/2020/03/Screen-Shot-2020-03-16-at-11.25.30-AM-1.png)




Products
Timescale is a reliable PostgreSQL cloud optimized for your business workloads.
Time series and analytics
PostgreSQL, but faster. Built for lightning-fast ingest and querying of time-based data.
Early accessVector (AI/ML)
PostgreSQL engineered for fast search with high recall on millions of vector embeddings.
Early accessDynamic PostgreSQL
PostgreSQL managed services with the benefits of serverless, but none of the problems.
Developers
Timescale is PostgreSQL, but faster. Learn the PostgreSQL basics and scale your database performance to new heights.
Subscribe to the Timescale Newsletter
By submitting, you acknowledge Timescale's Privacy Policy